CorA supports various types of annotations: part-of-speech tags, lemmatization, normalization, etc. — we refer to them as annotation layers (or, sometimes, tagsets1).
Annotation layers have to be associated with (or “linked to”) documents in order to use them. This way, you can customize which annotation columns should appear in the editor. You can also have multiple projects that use different layers, different POS tagsets, etc. These associations must be defined by an administrator, either in the project settings or, if needed, for individual texts.
Open vs. closed layers
An important distinction is that between open- and closed-class annotation layers:
-
Open annotation layers do not place restrictions on the possible annotation values. In the editor, they are typically represented by a text box which accepts arbitrary input.
Instances of these annotation layers are created automatically and can simply be selected when linking annotation layers to documents.
Example: lemmatization
-
Closed annotation layers have a fixed set of allowed annotation values. In the editor, values are typically selected from a dropdown box.
Because of this, instances of these annotation layers need to be created manually in the “Administration” tab by providing a name and a list of allowed values (‘tags’). This also means that, contrary to open-class layers, there can be several instances of the same closed annotation layer, but with different tag lists.
Example: POS
List of annotation layers
Here is a list of all annotation layers that CorA currently supports. Each layer has an internal “type”, i.e. a short abbreviation which identifies it. This type string is used when importing tagsets and also appears in XML tags when exporting documents in CorA-XML format.
| Name | Type | Class |
|---|---|---|
| Part-of-speech | pos | closed |
| Lemmatization | lemma | open |
| Lemma suggestion | lemma_sugg | closed |
| Lemma part-of-speech | lemmapos | closed |
| Normalization | norm | open |
| Modernization | norm_broad | open |
| Modernization type | norm_type | closed |
| Boundaries | boundary | closed |
| Comments | comment | open |
| Secondary comments | sec_comment | open |
Part-of-speech (POS)
Part-of-speech annotation in form of a closed tagset, optionally containing morphological information as well. In the editor, this annotation layer is represented by two separate columns: “POS” and “Morphology”. When making a selection in the “POS” dropdown box, the contents of the “Morphology” dropdown box change to only allow values that form legal tags with the chosen “POS” entry.
However, it is important to note that these two columns are conflated internally, and actually represent a single annotation of the value “<POS>.<Morphology>” — a dot (.) acts as a separator between the two.
In a tag value, everything preceding the first dot is considered to be the (base) “POS” tag, while everything following it is treated as belonging to “Morphology”. An exception is made for tags having a single dot at the end, because some tagsets use tags like “$.” for punctuation. When exporting documents to XML, POS tags are split up into “pos” and “morph” tags according to this rule.
Note that you are not required to use morphological attributes in your tags — it is perfectly fine to use tagsets with only plain POS tags; the “Morphology” column can be conveniently hidden in this case.
Lemmatization
Lemma annotation is an open annotation layer represented by a text box.
Lemmatization always comes with a lemma verification checkbox that turns green when you click on it. When entering a lemma, the system will search for suggestions based on identical tokens with a marked lemma verification checkbox in all texts within the current project, and display them in bold green:
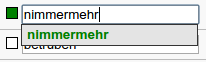
Lemma entry with marked verification checkbox and a lemma suggestion
The verification checkbox becomes unchecked when you modify the lemma entry, and becomes checked when you select a green (= verified) suggestion from the list.
Automatical lemma suggestions can also be provided by adding the lemma suggestion annotation layer.
Lemma suggestion
Provides auto-completion suggestions for lemma annotations.
Strictly speaking, this isn’t an annotation layer at all; rather, it provides an additional resource to another annotation layer, the lemmatization layer. When using lemma suggestions, the lemma text field will provide auto-completion suggestions to the user based on the string that he entered and the values in the lemma suggestion “tagset”. A maximum of twenty suggestions can be shown at a time.
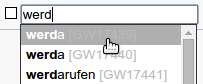
Auto-completion for lemmata based on a pre-defined list of lemma suggestions
In the auto-completion list, values in square brackets at the end of the string are displayed in light grey; a possible use case for this is IDs referring to an external lexicon. Apart from the distinctive rendering, these strings are not treated in any special way, though.
Special characters, such as accented letters, are conflated with their “simple” counterparts to a certain degree,2 so that entering ‘a’ in the lemma field would find auto-complete suggestions like ‘à’ or ‘âme’.
Lemma part-of-speech
Part-of-speech annotation for the lemmatization, in case you want to distinguish between POS annotation of the wordform versus the lemma.
Like the usual part-of-speech annotation, this is a closed tagset and represented by a dropdown box, but with two important differences:
-
It supports only one dropdown box (i.e., there is no such thing as “lemma morphology”).
-
If the lemma part-of-speech is empty and the user selects a (token) part-of-speech tag, the lemma POS field will auto-select the first entry that begins with the same string as the selected POS tag. (For example, if the user annotates part-of-speech with “VVIMP”, the lemma POS field might auto-select the tag “VV”, if such a tag exists.)
Normalization
Normalization is an open annotation layer represented by a text box, and intended for some kind of “standardized” form of the annotated token (e.g., modern forms of historical words, tokens with corrected spelling, long forms of abbreviations, …).
There is no special functionality attached to the text field, except that it can be used as input for external annotators in place of the original token.
Modernization
Modernization is an open annotation layer represented by a text box, and intended to be a “broader” form of normalization.
As long as it’s empty, the associated text box will show a grayed-out copy of the normalization field. This reflects our original intention that modernization only needs to be annotated if it would actually differ from normalization. In practice, since it is a simple text box, you can use the field in any way you like.
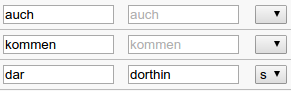
Normalization, modernization, and modernization type side-by-side
You can find more details about our own definition of “modernization” (as well as “modernization type”) in the following paper:
Julia Krasselt, Marcel Bollmann, Stefanie Dipper, and Florian Petran (2015). Guidelines für die Normalisierung historischer deutscher Texte / Guidelines for Normalizing Historical German Texts. Bochumer Linguistische Arbeitsberichte: 15.
Modernization type
Modernization type is a closed tagset, represented as a dropdown box that is conditioned on modernization: it is only active when the modernization field is filled.
Attention
It is not particularly useful to have a “modernization type” without “modernization”, since the dropdown box will always be disabled in this case.
It can be used to specify the type of content in the modernization column. You can find more details about our intended meaning of “modernization type” (as well as “modernization”) in the following paper:
Julia Krasselt, Marcel Bollmann, Stefanie Dipper, and Florian Petran (2015). Guidelines für die Normalisierung historischer deutscher Texte / Guidelines for Normalizing Historical German Texts. Bochumer Linguistische Arbeitsberichte: 15.
Boundaries
Boundary annotation consists of a check box combined with a dropdown box; the dropdown box is only active when the checkbox is checked.
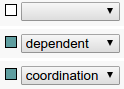
Boundary annotations
This layer is intended for marking structural boundaries, such as phrase, clause, or sentence boundaries. Activating the checkbox marks the respective token as a boundary, while the dropdown box can be used to further specify the type of boundary.
Comments / Secondary comments
Comments are represented by a text box that can be used in any way you wish. It grows larger while active (e.g. by clicking into it), to make it easier to read and write longer comments.
In case you’d like to distinguish between two types of comments (e.g. comments for internal use vs. comments to be included in a released corpus), there is another annotation layer for “secondary comments” which is functionally identical to “comments”.
List of flags
Flags are represented as checkboxes in the editor table that can be marked or unmarked. They can be bound to annotation layers and only appear when that layer is present, but they are treated separately from other annotations. Here is a list of the currently supported flags; follow the links to find out more about their intended usage. The internal ‘name’ string is used when representing flags in CorA-XML format.
| Function | Name |
|---|---|
| Generic error marking (‘E’) | general error |
| Lemma verification | lemma verified |
| Boundary marking | boundary |
-
To be precise, the character conflation happens in the database query, possibly depending on the MySQL version on the server, according to the “utf8_general_ci” collation chart. ↩